This is the eighth article in a series dedicated to the various aspects of machine learning. Today’s article will go in-depth on one of the most widely-used forms of machine learning, which is decision tree algorithms. This piece will offer insight into a few aspects of decision tree learning that define the way ML agents think.
A few articles ago, we covered the types of algorithms employed by a machine learning agent, our avatar being Domino’s delivery robot R2. We mentioned decision trees in that piece, which is a particular category of learning algorithm deserves an article of its own, due to its widespread use among ML agents and how it embodies the way an ML agent can reason.
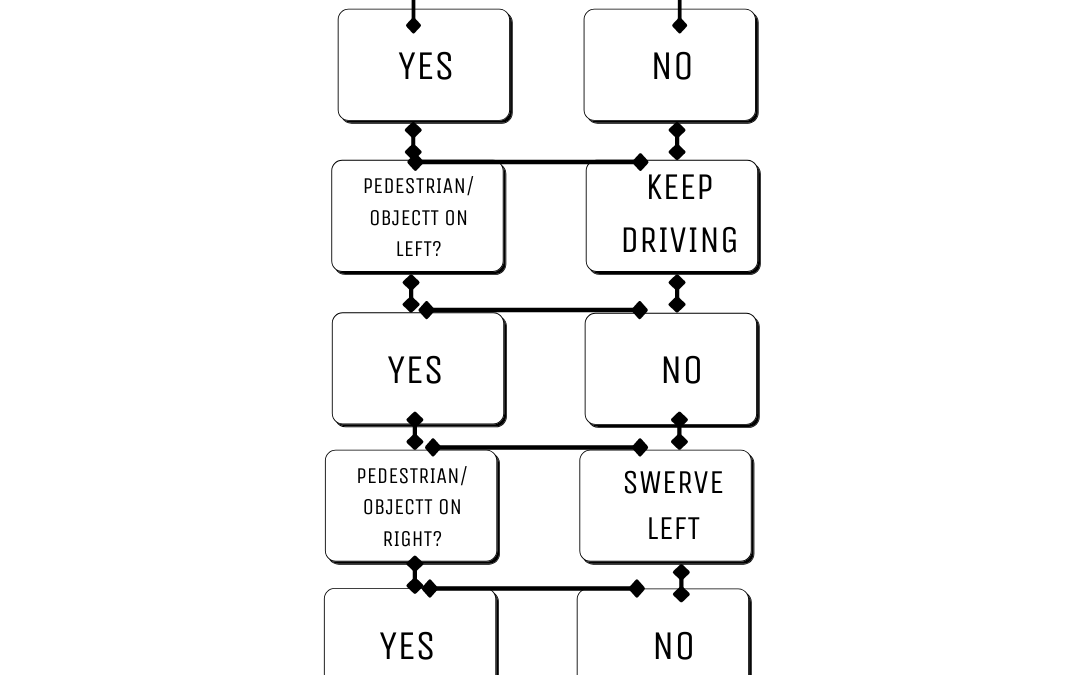
For a visual reminder of what a decision tree resembles, take a look below at our representation of R2’s decision-tree-assisted reasoning when it needs to respond to a dog running loose on the sidewalk:
Sees Dog?
^
Yes No
| |
Pedestrian/Object on Left? Keep Driving
^
Yes No
| |
Pedestrian/Object on Right? Swerve Left
^
Yes No
| |
Stop Swerve Right
Put simply, what decision trees do is represent the “decision(s)” that are available to an agent. It is unlike a human’s representation, perhaps, in that the decisions are in the form of a function that maps the values of the end-decision and the attribute values of that end-decision.
Most of us rely on our subjective feelings to make a decision, while a computer relies on objective measurements of “utility,” with the goal of choosing the decision that maximizes utility (doesn’t take up too much time, doesn’t disrupt the environment in a significant way, doesn’t use too much memory, etc.).
An end-decision is reached through tests that start at the “root” and follow the “branches” to “leaves” (starting to see why they call them decision trees?). Note that not all decision trees will be as sparse or short as the example above, and some can actually be quite complex.
Pruning
Something important to realize about ML agents is that the variety of input data can make quite a mess. Our conscious or unconscious mind will decide for us what information is relevant (e.g., the names of our relatives) and what can be forgotten (e.g., everything we learned in geometry, unless we now work a geometry-related job). A computer, on the other hand, is a storehouse for all kinds of data, and has no unconscious that will pick and choose what should be remembered and what shouldn’t.
As a result, irrelevant data can find itself in a decision tree. This needs to be recognized by an ML agent to stay efficient. Additionally, there can also be errors, referred to as “noise” in the machine learning world, that can offer faulty views of attributes in the tree.
The solution to dealing with irrelevant data is called “decision tree pruning,” and it gets rid of the “leaves” of irrelevant data. The end-goal of pruning is to minimize the number of branches that lead down to decision paths that end in bad decisions, and to save the agent the time of discovering these bad decisions in its search.
Attribute Tests
The ML agent can decide which “leaves” (which we should mention are formally called nodes) are irrelevant based on an attribute test, which measures the importance of an attribute.
Importance is defined in terms of entropy, which measures the uncertainty of a variable. So, the more information about a variable, then the less uncertainty there is about it, meaning less entropy.
Through an attribute test—we’ll save you the math-y explanation of how these tests are conducted—the ML agent will be able to find the information gain on an attribute, which means the expected reduction in entropy.
In short, the lower an information gain on a tested attribute, the more likely it is to be irrelevant.
ML agents can also use pruning and information gain to inform an early stop, which stops a decision tree from “branching out” any further from the nodes/leaves that are of low importance.
Other Machine Learning Tests
There are other tests run by ML agents to deal with the variety of data encountered.
Deciding where to split at a node can be tricky business. For continuous attributes, such as time, split point tests are run, which tests the inequalities in value of an attribute. An example of this would be testing to see if higher information gains are found when Time > 60 minutes or not.
Equality tests are used to pick out large data groups based on a single parameter, such as number of limbs. If number of limbs = 3, then the ML agent can pick the number of three-limbed people in the world and group the rest into their own tree.
Drawbacks of Decision Trees
Despite the helpful outline of attributes and their importance, decision trees are not always useful.
Sometimes it can lead to less-than-best solutions, mostly when greedy search is done. Greedy search is common, and is a search method that prioritizes finding the most utility-maximizing decisions in as quick a time as possible—saving both time and memory usage. This time-crunching method often finds good decisions, but not always the best.
Deep trees, where there are many branches and subbranches littered with leaves, can often be costly to run and maintain, and sometimes the expense required for making the best decision can be too high to justify.
Another issue is that the addition/discovery of new “leaves” can require the entire tree to be restructured, and can impact the root, even.
However, these issues can be resolved, or at least ameliorated, as we will cover in a later article in this series.
Machine Learning Summary
An ML agent’s relationship to decision trees is much more complex than simply running down the list of options and picking what seems best. It must modifying the trees through pruning, run tests in order to discern the values of the many options along the branches, and it needs to deal with the many complications posed by running a decision tree algorithms, such as the cost vs. benefit of performing a deep search of options.
Recent Comments